Chaos Engineering – A quick primer
Human body is vulnerable to lot of diseases. So in order to protect human beings from diseases vaccines have been invented. Vaccines mainly work due to process called 'Hormesis', by which system or organism adapts to harm in order to become stronger. Just as our body is susceptible to diseases and germs, so do our systems in software world. Hence vaccines and vaccination can be considered as an apt analogy for understanding Chaos Engineering. So as two part series on Chaos Engineering, we will try understanding the basics of Chaos Engineering in first part which will then be followed up by demonstrating working example in the second and final part of this series
What is Chaos Engineering?
Theoretical definition from Principles of Chaos
"Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system's capability to withstand turbulent conditions in production"
So in layman's term it is thoughtful, planned experiments executed in organized way to reveal weaknesses in software system. The whole purpose of being thoughtful, planned and organized is to be able to understand impact of experiments on system and thereby monitor system behavior. It is a scientific approach by which hypothesis about our systems are validated, which eventually helps us to discover significant information about our systems.
Just as different categories of tests help us build confidence in application, Chaos Engineering is a proactive way of validating our systems. Of course one would argue that we can still validate our systems by following the conventional and reactive approach to our operations during production incidents or outages. But this reactive approach will never get us to degree of reliability that we intend to.
Misconceptions
It is certainly not a lone wolf game where in one of the team members becomes a cow boy and runs into our system with all guns blazing pointed to our servers, database, infrastructure etc. Chaos engineering provides a platform to collaborate and thereby test communication boundaries - which not only includes technical but also include socio-technical boundaries. So it is certainly not to be done in a secretive fashion, just like James Bond's movies ;)
Why Chaos Engineering?
1. Potential Failure Points of System
Typically speaking, system can be mainly categorized into -
- Application Tier
- Caching Layer
- Database Tier
- Network
- Hardware
- Tools which are used for managing and operating software systems viz. Skype, Splunk, Self serving portals etc.
Most important thing to notice here is that all the above categories are not just falling in developer realm or QA realm or Devops realm. All of them will have to get together in order to build reliability into systems. All the above categories of system are vulnerable to failures. However, degree of vulnerability may vary.
2. Shift in Architecture paradigm
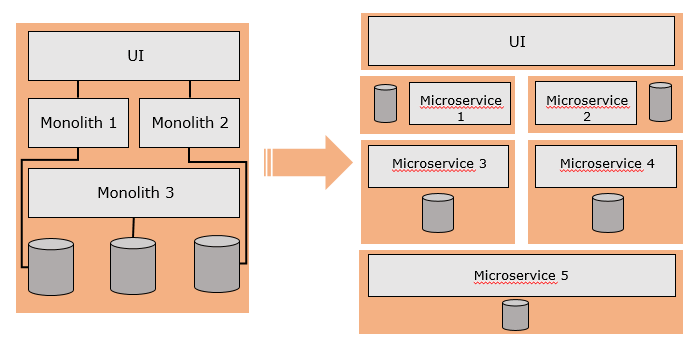
In today's contemporary world of software systems, most of the green field projects are built with Cloud Native Mircroservice architecture. And brown field projects are undergoing a major transformation i.e. moving from Monolithic architecture to Microservice architecture. With Microservice architecture there are lot of disconnected and moving pieces within the system. Now if we consider this shift in architecture paradigm through the lens of above failure points, there would be almost 6 * N failure points to deal with, where N is number of Microservice applications for a given system - needless to say that answer to this multiplication will look too substantial to ignore!
As per Murphy's law, failure in software systems is inevitable. So Chaos Engineering in a way helps to identify vulnerable areas within our system and thereby help us to either get rid of failures or reduce MTTR
Netflix, one of the pioneers of Chaos Engineering gave an excellent quote
Best way to avoid failure is to fail constantly
So Chaos Engineering allows to inject failures into the systems, that too on regular basis so that we can constantly identify weaknesses in our system and thereby harden them so that we are better prepared for production incidents or outages.
3. Predictability
Another compelling reason why Chaos Engineering should be performed is to have more predictability in our systems. In contemporary world our systems have become too disconnected. Variables in our system are myriad i.e. these variables may belong to user, infrastructure, network, hardware etc. and since we are unable to know all the variables within our system, we can not model and build system considering them - E.g. With public cloud based strategy we may not even own our hardware. So in order to bring more predictability, we need a mechanism to understand these variables of our system and thereby be better equipped for those unwanted and abrupt production incidents and outages
How to perform Chaos Engineering
1. Monitoring - An important prerequisite
One of the most important prerequisite to perform Chaos Engineering is to have state of the art Monitoring. It is advisable to refrain performing Chaos Engineering experiments if system does not have appropriate monitoring in place; as we may not be able to gather required system metrics that will help us to identify vulnerabilities and weaknesses which will eventually lead us to actionable insights
2. Game Day Planning
Basically chaos engineering will start with Planning a Game Day wherein we will have representatives from owners of the system (i.e. application, database, network, hardware, tools etc). Basic premise of this ceremony is to answer below questions -
- From system standpoint, what can go wrong or how can system fail?
- How to meticulously plan and effectively execute tests pertaining to answers that we get for above question?
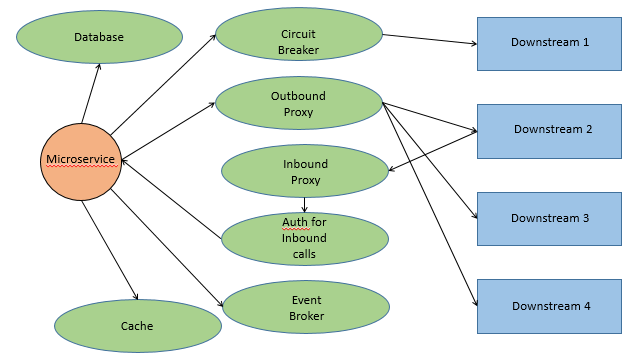
So as part of 1st question one should be coming up with application's system and infrastructure view. This will in a way help us to understand probable failure points within the system. Above image just represents infrastructure view of a typical Microservice application with a hypothetical scenario
Factors to be considered for identified probable failure points Now that we know how chaos engineering experiments should be executed, it is quite obvious that there can be zillions of failure points that can emerge as part of game day planning. But we may not want to perform chaos engineering experiments for all of them. There are 2 primary criteria which helps us decide on consideration of failure points for performing chaos engineering experiments -
Probability of its occurrence - Fundamental question that needs to be asked is how likely a failure can occur. It may be that certain failures are least likely. However, we may still want to be extremely sensitive to such rare failures by checking whether it can lead to black swan event and thereby have a catastrophic impact on organization
Cost of failure - Understanding cost of failure will in a way help to justify the effort spent for performing Chaos Engineering experiments in front of the organization's leadership.
Chaos Engineering Workflow
Chaos engineering has a very important fundamental that always needs to be kept in mind i.e. Blast Radius - which is nothing but the impacted area of system as an outcome of the chaos engineering experiments. In principle it should be as small as it can be so that chaos engineering experiments does not have a humongous impact, which is extremely complex and difficult to understand and analyze. So we should strive to run smallest possible experiment that can teach us something about our system's behavior.
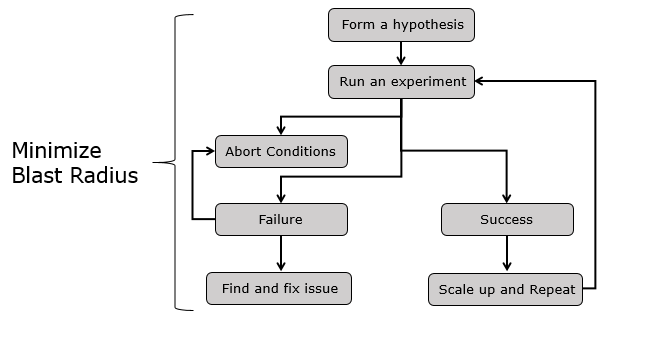
Similar to scientific experiments, Chaos Engineering typically starts with a hypothesis built around our system. And then we have set of experiments to validate our hypothesis. There are probable outcomes to our validation phase - Failure or Successful.
If validation of hypothesis ends up in failure which is not because of our experiment then we should abort our experiment. This is to ensure that we don't make the troubleshooting of the issue more ambiguous or complex due to multiple workflows triggered as part of our experiments. If our validation of hypothesis ends up with actual failure than we should be capturing all the required metrics and information that can help us analyze the vulnerabilities of our system. This will help us define some actionable items to harden different aspects of our system. If our validation of hypothesis ends up with success, we should be scaling up (i.e. we either change the blast radius or increase it) and repeat the validations.
Closing Thoughts
We tried understanding the WHAT'S, WHY'S and HOW's of Chaos Engineering with required rationale. So now we will be pretty much convinced that failures in software world are inevitable. And hence we need a mechanism to make our system better prepared to deal with them - That mechanism is none other than Chaos Engineering which will help us to identify potential weaknesses and vulnerability and thereby help us to harden them. This will be of immense help to be better prepared for production incidents and outages by either proactively getting rid of them or by reducing Mean Time To Recover (MTTR) from those unwanted incidents and outages.
In second part I will be demonstrating Chaos Engineering with a working example by following what we have learnt over here. So stay tuned!
comments powered by Disqus