Understanding Cloud Native Architecture with an example
Whenever the buzz word 'Cloud Native Architecture' gets to our ears, first thing that comes to our mind is - It sounds too jazzy and latest and would have something to do with technology since it has a word called 'Architecture' within it :). Because of this it creates a perception in the minds of lot of people that 'Cloud Native Architecture' is just about TECHNOLOGY. Unfortunately, this is one of the most common misconception that prevails currently in the industry.
Cloud Native Architecture is mainly about people, mindset and technology. As such there is no hard and fast definition for what exactly Cloud Native means. As per Joe Bida (Founder and contributor of Google Compute Engine and Kubernetes) -
'Cloud Native Architecture' is mainly about team structure, culture and technology to utilize automation and architectures to manage complexity and unlock velocity
So one would certainly wonder what exactly it takes to be 'Cloud Native'?
Matt Stine in his book “Migrating To Cloud-Native Application Architectures” describes about characteristics of cloud native applications -
- Is a 12-factor application
- Follows a Microservices architecture
- Uses self-service agile infrastructure – AKA a Platform-as-a-service
- Uses API-based collaboration
- Is anti-fragile
12 Factor Application
This is a methodology for building enterprise applications - generally speaking they are either web apps or SaaS. Twelve Factor apps are built for agility and continuous deployment, enabling continuous delivery and reducing the time and cost for all the stakeholders. At the same time, their architecture is built to exploit the principles of modern cloud platforms. Heroku is considered to be the early protagonist of these guidelines -
- Codebase - One codebase tracked in revision control, many deploys
- Dependencies - Explicitly declare and isolate dependencies
- Configuration - Store configuration in the environment
- Backing Services - Treat backing services as attached resources
- Build, release, run - Strictly separate build and run stages
- Processes - Execute the app as one or more stateless processes
- Port binding - Export services via port binding
- Concurrency - Scale out via the process model
- Disposability - Maximize robustness with fast startup and graceful shutdown
- Dev/prod parity - Keep development, staging, and production as similar as possible
- Logs - Treat logs as event streams
- Admin processes - Run admin/management tasks as one-off processes
These guidelines can be used as a starting point for being 'cloud native' and also as a yardstick to evaluate 'cloud native' readiness for any monolithic application.
Microservice Architecture
In order to overcome the perils of monolith viz. -
- Slower release cycles affecting business and market
- Time spent on regression testing for each new functionality and fix
- High build and deployment time of application which eventually slows down
- Handling catastrophic failures without affecting down time of application and user experience
- Addition of new hardware and resources without incurring additional and unnecessary cost
- Managing dependencies with minimal impact
- Ease of developer understanding
it is recommended to move towards Microservices Architecture. I think Martin Fowler and James Lewis describe it best:
"In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API"
Self Service Agile Infrastructure
In order for the team and release to be really Agile, infrastructure also needs to be agile; which can only be achieved with PaaS. Since we are going to have set of independent services (i.e. application) which will have its own life cycle, it is recommended to have a very streamlined way of providing right infrastructure to these (micro)services - as we are going to have more than 100s of services to be deployed for our application to work. One can leverage various options for PaaS that are available in market viz. Pivotal Cloud Foundry, Amazon Web Service, Microsoft Azure etc.
Uses API based collaboration
With Microservices based approach we are going to have myriad set of services and each of these services will internally collaborate over REST based API contracts. Reason why it is not recommended to go with method based API contracts is that, it will make microservices more invasive in nature and thereby increase inter dependency among them. Also the nature of usage of each of these services might require to have its own hardware and processing capabilities
Is Anti-fragile
For any application, expected uptime is 99.999%, however if we are ready to accept reality than we clearly know that applications are bound to go down and hence they are inevitable - as Googles, Facebooks and Twitters also go down. Most important characteristics of High Available systems is - how gracefully they are able to handle such failures and how quickly they are able to recover. So the architecture (including infrastructure) has to be resilient in nature and has to be implemented by keeping such failures in mind.
Tenets of Cloud Native Architecture
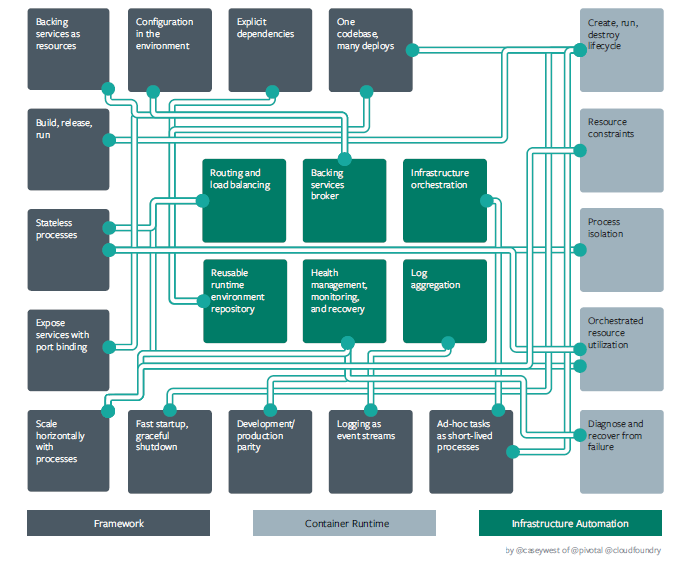
Courtesy - Casey West
So cloud is a platform which manages everything i.e. infrastructure for each service, packaging and deployment of applications, observability of applications sharing key insights on its health, usage etc. So considering technology aspects of 'Cloud Native Architecture', it mainly comprises of -
- Framework
- Container Runtime
- Infrastructure Automation
Where is the code honey? :)
For all the technologists you may feel - 'All the guidelines and principles sounds logically cool !' :) But can we get to see an example that can help us understand above fundamentals of 'Cloud Native Architecture'?
So answer to the above question is YES !
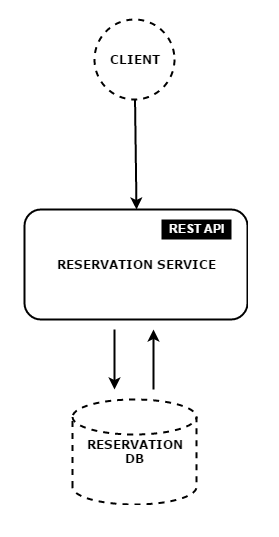
For sake of simplicity we will be just having a single service for Reservation which has following set of services -
| Method | URI | Description | User Authenticated | Available from UI |
|---|---|---|---|---|
| GET | /reservations/names | Fetches entire list of reservations done by user | X | X |
| POST | /reservations/ | Creates reservations for a given user | X |
From functional stand point this is how simplistic the service would look like
However, from 'Cloud Native' architectural standpoint, this is how our implementation would span out which includes application services (boxes with bold borders) and infrastructure services (boxes with dotted lines as borders) !

Technology Stack
It will be an all Spring technology stack that I will be using for implementing the example
Actual source code of example can be availed at my Github account and detailed information on the implementation along with its brief description can be referred within its README file
Note - The implementation is an as is adaptation from Josh Long's session on 'Cloud Native Java' conducted during Spring One Platform 2016 along with some additional infrastructure service in the form of 'Microservices Dashboard'.
comments powered by Disqus