Unraveling the magic behind Spring Boot
Considering the extensive usage of Spring Boot for building Cloud Native Architecture, I embarked on the journey of utilizing it in my reference Cloud Native application. When I ran my first application I was literally flabbergasted with the magic Spring Boot does under the hood, using which it camouflages the complexity and challenges of building enterprise applications. In order to understand capabilities of Spring Boot and thereby have its justifiable usage along with its troubleshooting skills I felt a dire need of demystifying the magic behind it!
The thing that makes an app a Spring boot application is the annotation @SpringBootApplication. This is basically applied to the class having main method i.e. entry point of the application. It is a meta annotation which internally comprises of 3 annotations -
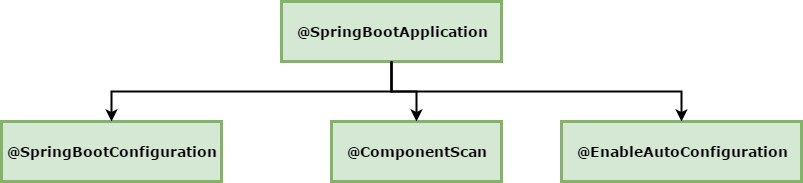
- @SpringBootConfiguration - Its a specialization of spring framework's configuration annotation and it mainly helps in automatically discovering Spring configurations
- @ComponentScan - Its a core spring framework standard component scan annotation.
- @EnableAutoConfigurations - It primarily switches on Spring boot's intellectual configurations based on class path, properties that has been configured
1package com.its.hello;
2
3import org.springframework.boot.SpringApplication;
4import org.springframework.boot.autoconfigure.SpringBootApplication;
5
6@SpringBootApplication
7public class HelloApp {
8
9 public static void main(String\[\] args) {
10 SpringApplication.run(HelloApp.class,args);
11 }
12}@ComponentScan
So in this example we have HelloApp within com.its.hello package annotated with @SpringBootApplication. So all the components (i.e. classes annotated with @Component) underneath package com.its.hello or its sub packages (e.g. com.its.hello.alpha etc.) will be picked up via component scanning. So in nutshell, this gets triggered as a part of @SpringBootApplication
1package com.its.hello;
2
3import org.springframework.boot.SpringApplication;
4import org.springframework.context.annotation.ComponentScan;
5import org.springframework.context.annotation.Configuration;
6
7@Configuration
8@ComponentScan
9public class HelloApp {
10
11 public static void main(String\[\] args) {
12 SpringApplication.run(HelloApp.class,args);
13 }
14}If application does not require auto configuration, one can still create an application without @SpringBootApplication i.e. by using @Configuration and @ComponentScan
So within a package you not only find Component but you will also find other annotations which are specializations of component i.e.
- @Bean
- @Repository
- @Configuration
- @Controller
- @Service
- @RestController
All these annotations will mainly create beans within your application context.
When any spring application bootstraps, it will be able to scan all the specializations of Component (as indicated above). i.e. Apart from @Component and @Bean, it will also look for @Configuration classes and bean methods declared within Component and its specialization. So all of these together constitute to form beans pertaining to user configurations within application context. What's in for migrating legacy Spring projects - There is a provision regarding usage Import annotation which will allow direct reference to xml file. And by this one can still keep its wiring within configurations file i.e. xml and refer it within Spring boot application. This facilitates gradual migration instead of a big bang migration.
Guidelines
- It is strongly recommend to have dedicated package for each application and thereafter put your Spring Boot application at the root of application.
- For any spring boot application its very common gotcha when a new component or package is created and it is not picked up by spring boot application. So its worth checking whether the component created is in the same package where spring boot application is created or any of its sub packages.
- It not only supports scanning components with @Configuration but it can also support Spring's XML based configuration i.e. context:component-scan. So it mainly provides user configuration i.e. beans which are created as a part of business workflow can be
@EnableAutoConfigure
Auto configurations are switched on using @EnableAutoConfiguration annotation, which will be implicitly done if we are using @SpringBootApplication. So this in a way will also create set of beans within application context. It is an auto configuration which intellectually configures beans that are likely to be required by the application.
Important point to keep in mind is these are i.e User Configuration and Auto Configuration are two disparate steps / processes that happen whilst creation of application context and that too in a chronological order i.e. initially beans related to user configuration gets created first and then the beans related to auto configuration gets created.
Lets create a Configuration class which is neither going to be scanned, nor going to be referred via import statement. Instead we are going to register it with specific file, that Spring Boot will look on our classpath during application bootstrap.
1package hello.autoconfigure;
2
3import hello.ConsoleHelloService;
4import hello.HelloService;
5import org.springframework.context.annotation.Bean;
6import org.springframework.context.annotation.Configuration;
7
8
9@Configuration
10public class HelloAutoConfiguration {
11
12 @Bean
13 public HelloService helloService() {
14 return new ConsoleHelloService();
15 }
16}For enabling auto configuration one needs to add a value for the key named org.springframework.boot.autoconfigure.EnableAutoConfiguration within src/main/resources/META-INF/spring.factories file. Value is a comma separated list of fully qualified name of auto configuration classes that you want to switch on by enabling it via @EnableAutoConfigure
1org.springframework.boot.autoconfigure.EnableAutoConfiguration=hello.autoconfigure.HelloAutoConfigurationThis is Spring Boot's standard mechanism for enabling auto configuration.
Auto configuration with condition(s)
1package hello.autoconfigure;
2
3import hello.ConsoleHelloService;
4import hello.HelloService;
5import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
6import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
7import org.springframework.context.annotation.Bean;
8import org.springframework.context.annotation.Configuration;
9
10@Configuration
11@ConditionalOnClass(HelloService.class)
12public class HelloAutoConfiguration {
13
14 @Bean
15 @ConditionalOnMissingBean
16 public HelloService helloService() {
17 System.out.println("Entering HelloAutoConfiguration : helloService");
18 System.out.println("Instantiating ConsoleHelloService and leaving HelloAutoConfiguration : helloService");
19 return new ConsoleHelloService();
20
21 }
22}@ConditionalOnMissingBean : It indicates that this bean will only be created only when there is no other bean of type HelloService within application context
@ConditionalOnClass (HelloService.class) : Before instantiation of any bean one can always validate whether all the prerequisites are present. Lets take a hypothetical scenario wherein auto configuration code is separate from services. So in that case one can still safe guard auto configuration instantiation by putting @ConditionalOnClass
Within Spring, there can be multiple conditions on a given class / method, these conditions are evaluated in a specific order (as mentioned below) :
- @ConditionalOnClass
- @ConditionalOnMissingClass
- @ConditionalOnResource
- @ConditionalOnJNDI
- @ConditionalOnWebApplication
- @ConditionalOnProperty
- @ConditionalOnExpression
- @ConditionalOnSingleCandidate
- @ConditionalOnBean
- @ConditionalOnMissingBean
Bottom three i.e. @ConditionalOnSingleCandidate, @ConditionalOnBean and @ConditionalOnMissingBean are performance intensive as their corresponding validations need to be done at application context level i.e. they are dependent on the state of application context; Hence one needs to be extremely cautious in terms of its usage. Rest all of them are related to infrastructure / environment.
Auto configuration with property file(s)
1package hello.autoconfigure;
2
3import org.springframework.boot.context.properties.ConfigurationProperties;
4
5@ConfigurationProperties("hello")
6public class HelloProperties {
7 private String prefix;
8 private String suffix = "!";
9
10 public String getPrefix() {
11 return prefix;
12 }
13
14 public void setPrefix(String prefix) {
15 this.prefix = prefix;
16 }
17
18 public String getSuffix() {
19 return suffix;
20 }
21
22 public void setSuffix(String suffix) {
23 this.suffix = suffix;
24 }
25
26}Configuration properties are simple POJOs which asks spring boot to bind environment with POJO instance via certain key. In our above example hello is the key through which we can refer HelloProperties and thereby set its attributes.
Ordering within Auto Configuration
If there is a need to maintain order in terms of instantiating multiple Auto Configurations, Spring Boot allows to ensure its chronological sequence by using @AutoConfigureAfter and @AutoConfigureBefore
Understanding auto configuration report
For getting auto configuration report, we need to run our spring boot app in debug mode. And on successful start of an application, spring boot will emit quiet exhaustive logging which will in turn help us to understand the configurations of the application. It not only tells us about positive matches but also conveys about negative matches i.e. the one for which dependencies are not present. Look at the snapshot of auto configuration report extracted from the console logs
1=========================
2AUTO-CONFIGURATION REPORT
3=========================
4
5
6Positive matches:
7-----------------
8
9 GenericCacheConfiguration matched:
10 - Cache org.springframework.boot.autoconfigure.cache.GenericCacheConfiguration automatic cache type (CacheCondition)
11
12 HelloAutoConfiguration#helloService matched:
13 - @ConditionalOnMissingBean (types: hello.HelloService; SearchStrategy: all) did not find any beans (OnBeanCondition)
14 - ValidHelloPrefix valid prefix ('Howdy') is available (OnValidHelloPrefixCondition)
15
16 JmxAutoConfiguration matched:
17 - @ConditionalOnClass found required class 'org.springframework.jmx.export.MBeanExporter'; @ConditionalOnMissingClass did not find unwanted class (OnClassCondition)
18 - @ConditionalOnProperty (spring.jmx.enabled=true) matched (OnPropertyCondition)
19
20 JmxAutoConfiguration#mbeanExporter matched:
21 - @ConditionalOnMissingBean (types: org.springframework.jmx.export.MBeanExporter; SearchStrategy: current) did not find any beans (OnBeanCondition)
22
23 JmxAutoConfiguration#mbeanServer matched:
24 - @ConditionalOnMissingBean (types: javax.management.MBeanServer; SearchStrategy: all) did not find any beans (OnBeanCondition)
25
26 JmxAutoConfiguration#objectNamingStrategy matched:
27 - @ConditionalOnMissingBean (types: org.springframework.jmx.export.naming.ObjectNamingStrategy; SearchStrategy: current) did not find any beans (OnBeanCondition)
28
29 NoOpCacheConfiguration matched:
30 - Cache org.springframework.boot.autoconfigure.cache.NoOpCacheConfiguration automatic cache type (CacheCondition)
31
32 PropertyPlaceholderAutoConfiguration#propertySourcesPlaceholderConfigurer matched:
33 - @ConditionalOnMissingBean (types: org.springframework.context.support.PropertySourcesPlaceholderConfigurer; SearchStrategy: current) did not find any beans (OnBeanCondition)
34
35 RedisCacheConfiguration matched:
36 - Cache org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration automatic cache type (CacheCondition)
37
38 SimpleCacheConfiguration matched:
39 - Cache org.springframework.boot.autoconfigure.cache.SimpleCacheConfiguration automatic cache type (CacheCondition)
40
41 SpringApplicationAdminJmxAutoConfiguration matched:
42 - @ConditionalOnProperty (spring.application.admin.enabled=true) matched (OnPropertyCondition)
43
44 SpringApplicationAdminJmxAutoConfiguration#springApplicationAdminRegistrar matched:
45 - @ConditionalOnMissingBean (types: org.springframework.boot.admin.SpringApplicationAdminMXBeanRegistrar; SearchStrategy: all) did not find any beans (OnBeanCondition)
46
47
48Negative matches:
49-----------------
50
51 ActiveMQAutoConfiguration:
52 Did not match:
53 - @ConditionalOnClass did not find required classes 'javax.jms.ConnectionFactory', 'org.apache.activemq.ActiveMQConnectionFactory' (OnClassCondition)
54
55 AopAutoConfiguration:
56 Did not match:
57 - @ConditionalOnClass did not find required classes 'org.aspectj.lang.annotation.Aspect', 'org.aspectj.lang.reflect.Advice' (OnClassCondition)
58
59 ArtemisAutoConfiguration:
60 Did not match:
61 - @ConditionalOnClass did not find required classes 'javax.jms.ConnectionFactory', 'org.apache.activemq.artemis.jms.client.ActiveMQConnectionFactory' (OnClassCondition)
62
63 BatchAutoConfiguration:
64 Did not match:
65 - @ConditionalOnClass did not find required classes 'org.springframework.batch.core.launch.JobLauncher', 'org.springframework.jdbc.core.JdbcOperations' (OnClassCondition)
66...
67..
68.Looking at the positive matches we are able to see custom auto configuration we have implemented for our application along with its custom conditions.
Event Life Cycle of Spring Boot applications
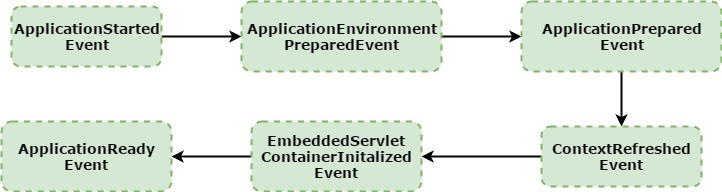
Lets try understanding different events that gets published once spring boot application bootstraps -
- When spring boot application runs, first thing that happens is ApplicationStartedEvent is published. This is the point where Logging initialization begins
- Next thing that happens is, ApplicationEnvironmentPreparedEvent is published. This means that environment is created which consists of default set of property sources. This is the standard list of property sources one can get from spring framework. As one observes till here, nothing specific to Spring boot has happened within the environment. So there will be 2 property source in there - One for environment variables and other for system properties. So far just the environment has been created. Neither the application context nor the beans have been created so far; and not even the context is refreshed yet. Next step within this will be to read config files. This is where spring boot specific things get started. i.e. it start reading application.properties / application.yml files and the profile specific variants if any. Within spring boot you can make profile specific property files - e.g. application.properties, application-
.properties . So profile specific application.properties will be read only when profile is active. So this in a way allows to construct beans based on a specific profile. So this is useful in scenarios where one wants certain set of configurations for certain environments - e.g. In dev environment one want to enable debug logs, or tells hibernate to display sql statements etc. So now all the config files are read and also one or more property sources are read. This is where ordering of property sources helps. So in layman's terms profile specific property source (e.g. application-dev.properties) will always take precedence against your general property source (e.g. application.properties). At this point, environment has been setup and now its in default form for spring boot; so it has property source for configured environment and also property source for system properties. It also has got config files that it has read in. And this environment is passed to all the configured post processors within _META-INF/spring.factories. _Now the logging initialization formally would get completed. Rationale behind not completing logging initialization earlier is due to the fact that logging settings (i.e. log level, lot pattern etc.) can be configured within configuration files - kind of a chicken and egg problem :) - Next thing that happens is we fire ApplicationPreparedEvent i.e. spring boot says, I have done all the setup as a part of environment preparation. And at this point, application context is refreshed i.e. bean starts getting created, dependency injection happens etc.
- Now spring framework's ContextRefreshedEvent is fired. All the previous events were spring boot specific. Embedded servlet container connectors are started now.
- EmbeddedServletContainerInitializedEvent gets fired next. So now once the container along with its connectors are up and running, this event is published which mainly encapsulates port (local.server.port variable) on which container has started. It also updates the environment with above variable (i.e. local.server.port)
- Last of all is the ApplicationReadyEvent is published - it just says application is up and running - Context is refreshed, server is bootstrapped, connectors are started, published local server port property.
This is just an article that emits my learnings and understanding that I was able to do as a part of viewing and following the talk given by Stephen Nicoll and Andy Wilkinson
Source Code - here.