Parallel processing - A comparative analysis

Background
If you've ever had to implement business logic that involves concurrent execution along with heavy IO operations, you'll know it can be challenging! Recently, I had a chance to tackle such a use case and made some interesting discoveries about parallel execution in the Java ecosystem.
I'll keep this concise and focus on three main areas:
- Understanding What part of requirements
- High level overview of available solutions
- Comparative analysis of available solutions from software & performance engineering standpoint
1. Understanding what part of overall requirements
At a high level, the requirement were:
- Implement a business logic that reads objects from a list.
- For each object, perform IO-intensive operations by invoking multiple downstream system APIs.
- Each object's logic is independent of the others.
- A maximum of 10 downstream APIs to be invoked per object.
2. High level overview of available solutions
The solution seemed straightforward - iterate the list and execute the business logic in parallel for each object. As a Java / Spring engineer, I considered two options:
- JDK 21based implementation
- Spring Core Reactor based implementation
2.1 JDK Based implementation
Excerpt from actual code
1 public static void withFlatMapUsingJDK() {
2 ...
3 // Define thread pool
4 ExecutorService executorService = Executors.newFixedThreadPool(AppConstants.PARALLELISM);
5
6 // Submit tasks for parallel processing
7 List<CompletableFuture<Void>> futures =
8 objectList
9 .stream()
10 .map(anObject -> CompletableFuture.runAsync(() -> {
11 try {
12 log.info("Processing object: {}", anObject);
13 processSomeBizLogic(anObject);
14 successCount.incrementAndGet();
15 } catch (Exception e) {
16 log.error("Error occurred while processing object {} : {}", anObject, e.getMessage());
17 failureCount.incrementAndGet();
18 }
19 }, executorService))
20 .toList(); // Collect CompletableFuture<Void> for each object
21
22 // Wait for all tasks to complete
23 CompletableFuture<Void> allOf = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
24 try {
25 allOf.join();
26 } catch (Exception e) {
27 log.error("Error waiting for all tasks to complete: {}", e.getMessage());
28 }
29
30 // Shut down the executor
31 executorService.shutdown();
32
33 // Log results
34 log.info("Success count: {}", successCount.get());
35 log.info("Failure count: {}", failureCount.get());
36 log.info("## Processing completed for object list size : {} ", objectList.size());
37 ...
38 }
Overview of parallel execution using CompletableFuture
- Thread Pool (
ExecutorService): UsedExecutors.newFixedThreadPool(4)to process objects (read from list) in parallel with a fixed number of threads - Parallel Processing (
CompletableFuture): Each object is processed in parallel usingCompletableFuture.runAsync - Error Handling: Exceptions thrown during processing are caught within the
CompletableFuture.runAsyncblock, and failure counts are incremented. Errors are isolated to individual tasks and hence do not affect other threads. - Wait for Completion: Used
CompletableFuture.allOfto wait for all tasks to complete.
2.2 Spring Core Reactor based implementation
Excerpt from actual code
1 ...
2 Flux
3 .fromIterable(objectList)
4 .parallel(AppConstants.PARALLELISM)
5 .runOn(Schedulers.boundedElastic())
6 .flatMap(anObject ->
7 Mono.fromCallable(() -> {
8 log.info("Entering processSomeBizLogic from Callable : {} ", anObject);
9 processSomeBizLogic(anObject);
10 log.info("Leaving processSomeBizLogic from Callable : {}", anObject);
11 successCount.incrementAndGet();
12 return anObject;
13
14 })
15 .doOnError(error -> {
16 log.error("Error occurred while processing object {} : {}", anObject, error.getMessage());
17 failureCount.incrementAndGet();
18 })
19 .onErrorResume(error -> {
20 log.info("Entering onErrorResume");
21 return Mono.empty();
22 }) // Skip the errored object
23 )
24 .sequential()
25 .doOnComplete(() -> {
26
27 log.info("Success count: {}", successCount.get());
28 log.info("Failure count: {}", failureCount.get());
29 log.info("$$ Processing completed for object list size : {} ", objectList.size());
30 })
31 .blockLast();
32 ...
Overview of parallel execution using Flux
- With
flatMap: This operator allows us to handle errors on per-item basis. Each item is wrapped inMono.fromCallableto enable the error handling flow. - Error Handling with
doOnErrorandonErrorResume:doOnError: Logs the error details for the specific itemonErrorResume: Ensures that errors are skipped by returning an empty Mono. Errors in one thread will not affect the processing of other thread
- Parallel Execution: The
parallel(4).runOn(Schedulers.boundedElastic())ensures that processing happens in parallelSchedulers.boundedElastic(): Creates a bounded thread pool that can adjust based on demand, preventing resource exhaustion
3. Comparative analysis of available solutions from software & performance engineering standpoint
The main difference between these solutions is the cleanliness and elegance of the Flux based implementation, which avoids boilerplate code with its fluent APIs. However, it’s important to have tangible criteria to compare alternatives, such as performance, scalability, resilience etc.
So in quest of determining more tangible factors to compare alternatives under considerations - I started delving bit deeper to evaluate available options through the lens of performance engineering. Hence I measured performance of processing entire list in parallel with -
- 1,00,000 objects
- 2,50,000 objects
- 5,00,000 objects
3.1 Total time spent in processing entire list
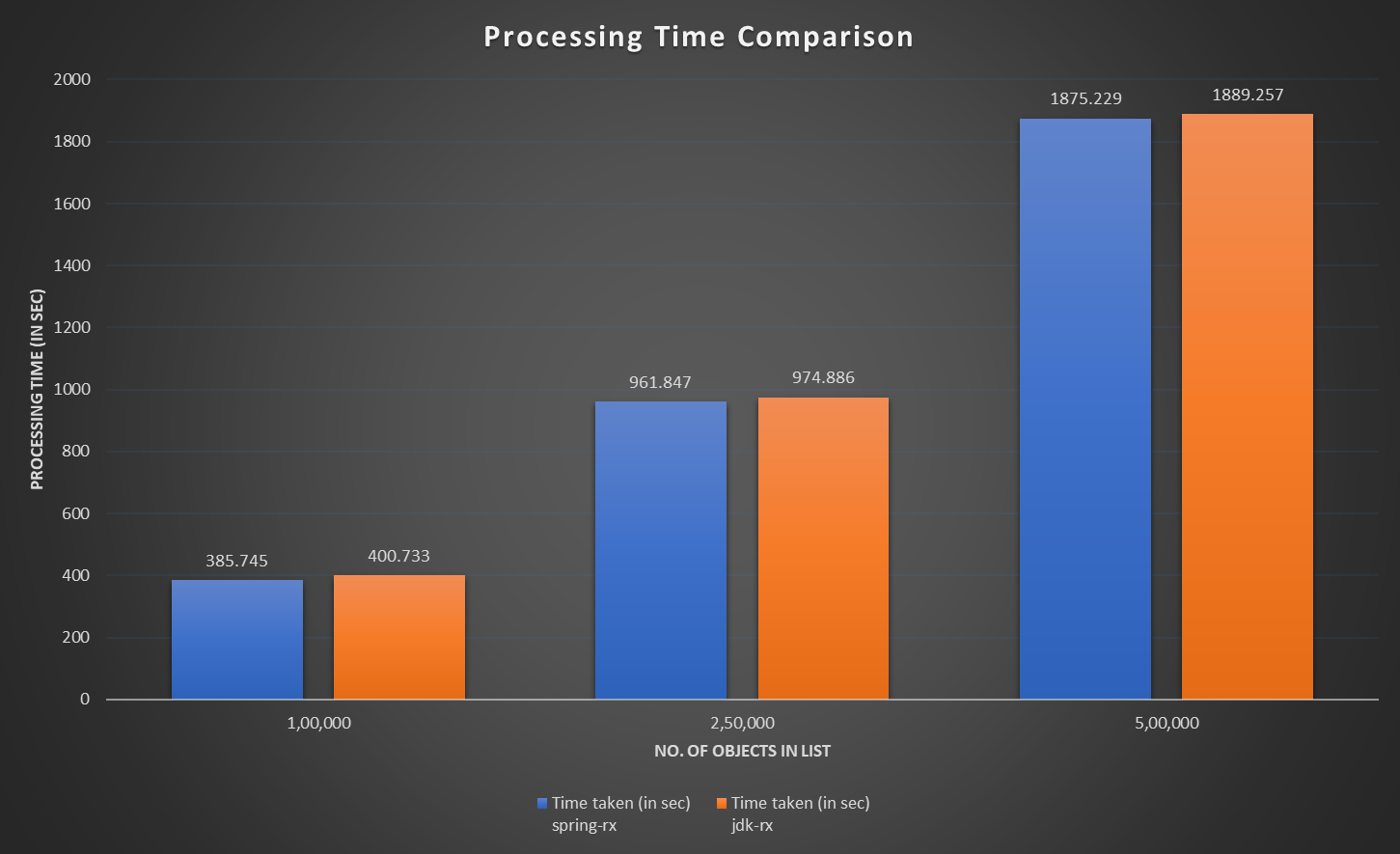
As we can see in above graph - Spring Reactor processes the list faster. JDK's performance doesn’t exponentially degrade with an increasing list size.
3.2 Memory footprint
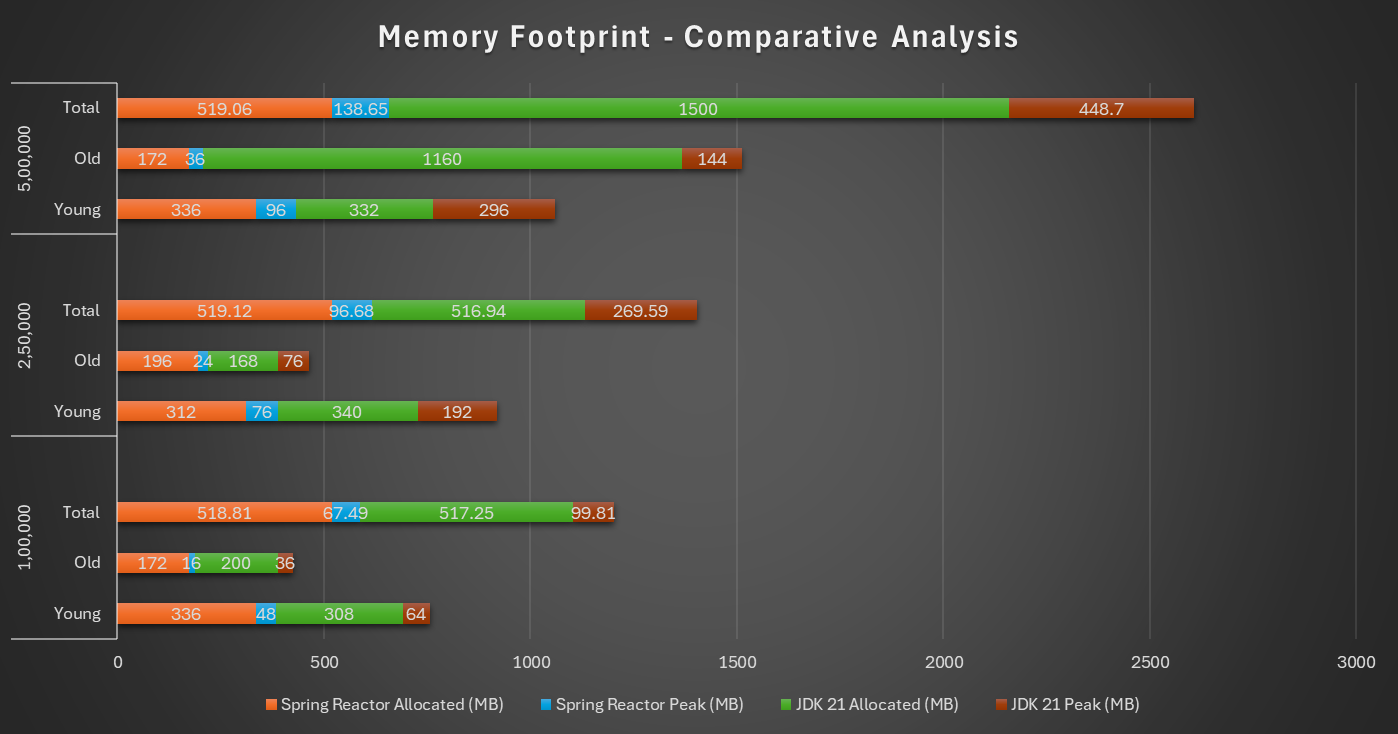
From above graph one can clearly infer -
- For 5 lac objects, JVM is required to allocate 3 times more memory for JDK based implementation as compared to Spring Reactor based implementation
- Percentage increase w.r.t Peak Memory is exponentially increasing with list size in JDK
3.3 GC Metrics
As we have seen in my previous blogs, GC has a significant impact on performance of an application. Here's how they compare:
3.3.1 GC Pauses
This mainly indicates amount of time taken by STW GCs.
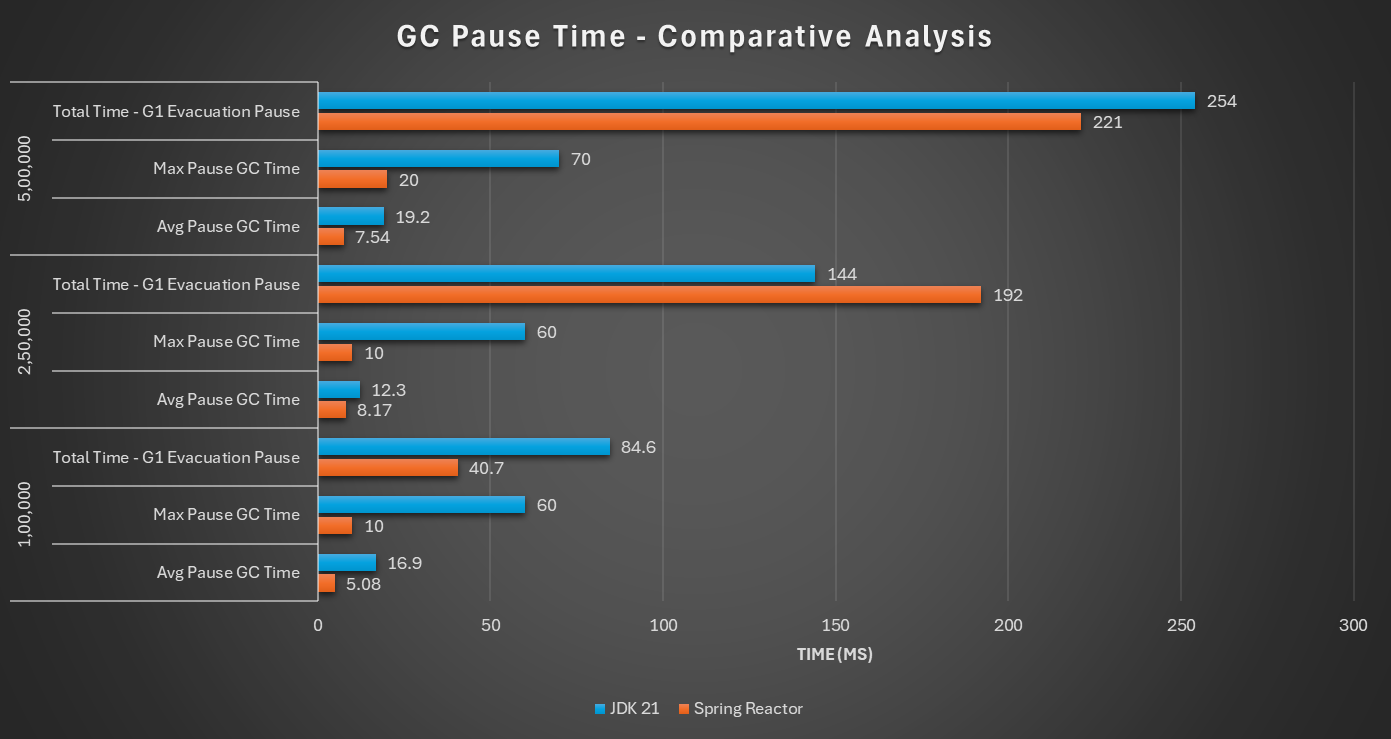
Comparatively speaking, in most of the cases GC pauses are higher for JDK based implementation.
3.3.2 CPU Time
This shows total CPU time taken by garbage collector.
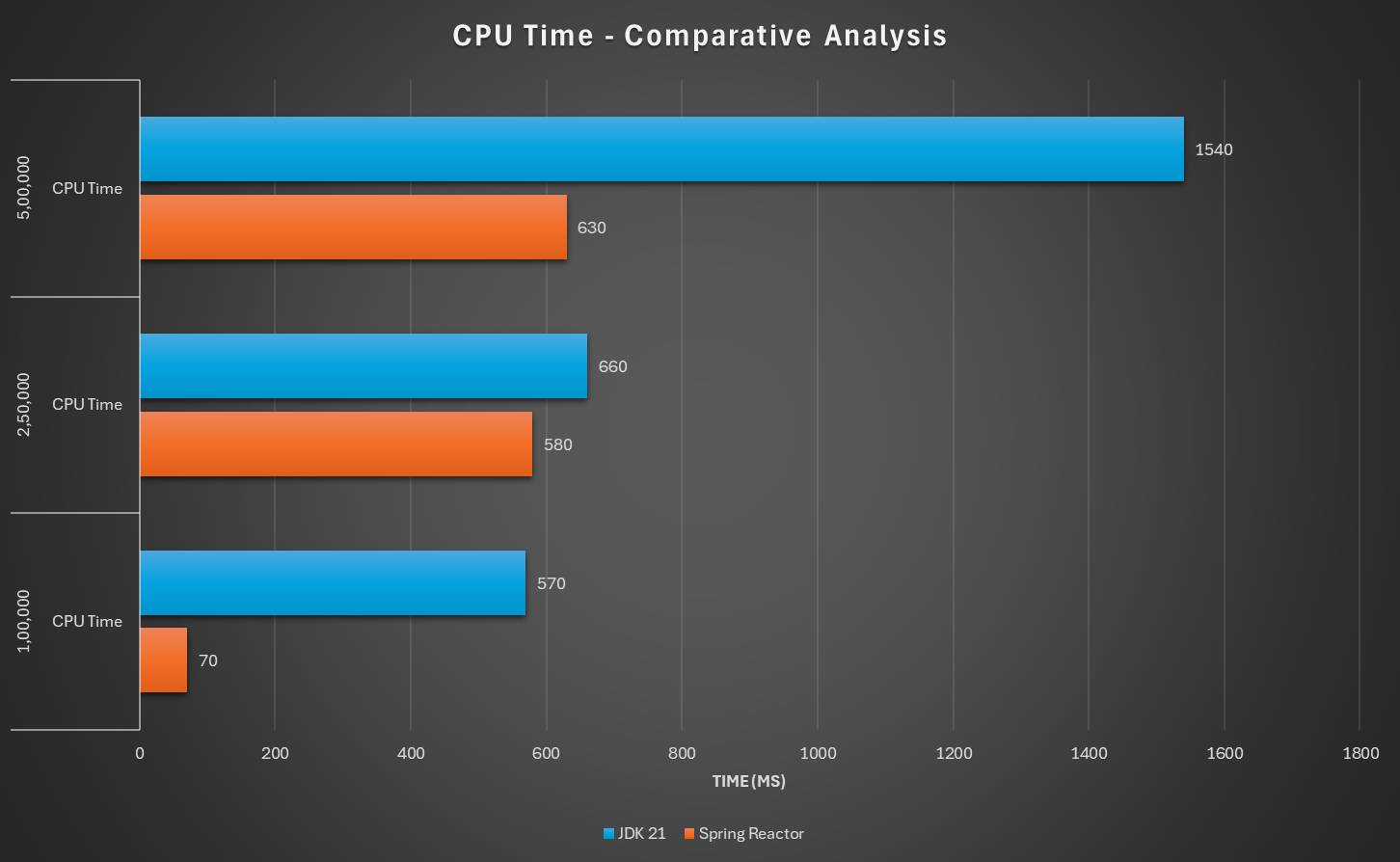
It is evident from above graph that JDK based implementation is requiring higher CPU time for its GC activities.
3.3.3 Object Metrics
This shows rate at which objects are created within JVM heap and rate at which they are promoted from Young to Old region.
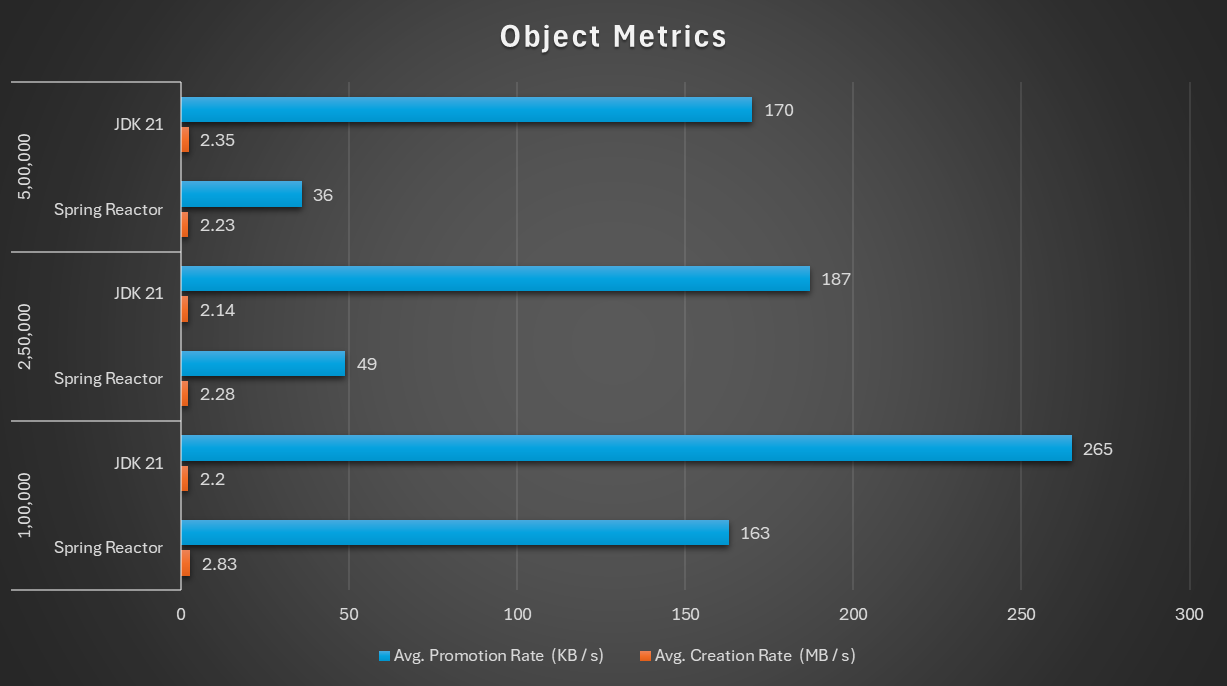
An interesting behavior that can be inferred - Even though object creation rate has been higher for Spring Reactor based implementation, object promotion rate is way less when compared with JDK based implementation.
Conclusion
After objectively comparing both the solutions, it is quite apparent that Spring Reactor based implementation is not only clean and elegant but also performs better.
P.S - All the graphs shown above are prepared by using data from GC report generated by GCEasy
comments powered by Disqus